Open Monkey Mind software
OpenMonkeyMind (OMM) is a framework for distributing OpenSesame experiments for automated behavioural testing in primates.
omm-client is installed on each testing module; omm-server is installed on a single machine piloting all modules, such that a monkey can access his next trial on any testing module. All data is saved centrally.
MarmAudio: A large annotated dataset of vocalizations by common marmosets
We present here MarmAudio, a database of common marmoset vocalizations, which were continuously recorded with a sampling rate of 96 kHz from a stabulation room housing simultaneously ~20 marmosets in three cages. The dataset comprises more than 800,000 files, amounting to 253 hours of data collected over 40 months. Each recording lasts a few seconds and captures the marmosets’ social vocalizations, encompassing their entire known vocal repertoire during the experimental period. Around 215,000 calls are annotated with the vocalization type. We validated our dataset by sampling 700 representative recordings and cross-examining them with four experts.


PrimaVoice: A Cross-Species Stimulus Set to Study Voice Processing in Primates
Audio stimulus set comprising four main categories: human voices, macaque vocalizations, marmoset vocalizations and non-vocal sounds, each containing 24 stimuli, for a total of 96 sound stimuli. Each main category is divided into 4 subcategories of 6 stimuli, forming 16 subcategories in total.
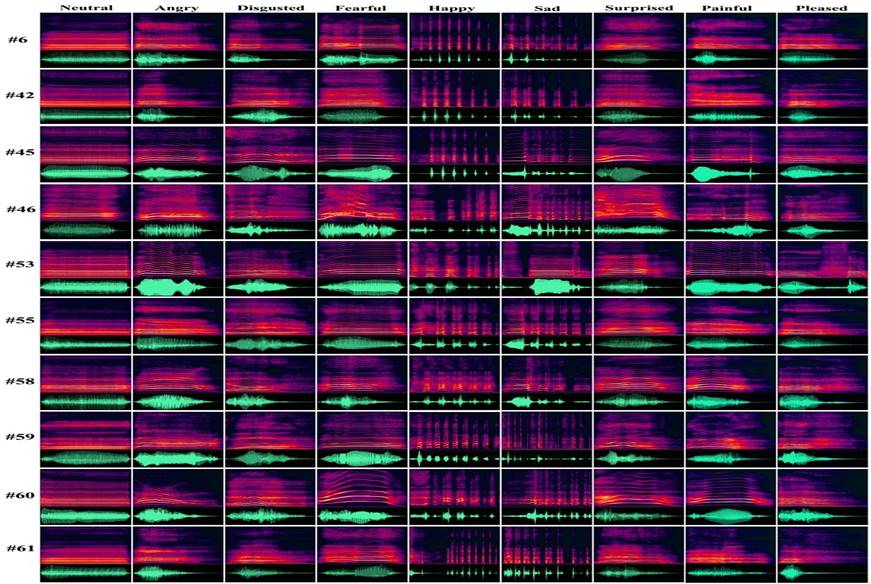
The Montreal Affective Voices
The Montreal Affective Voices consist of 90 nonverbal affect bursts corresponding to the emotions of anger, disgust, fear, pain, sadness, surprise, happiness, and pleasure (plus a neutral expression), recorded by 10 different actors (5 of them male and 5 female). Ratings of valence, arousal, and intensity for eight emotions were collected for each vocalization from 30 participants.
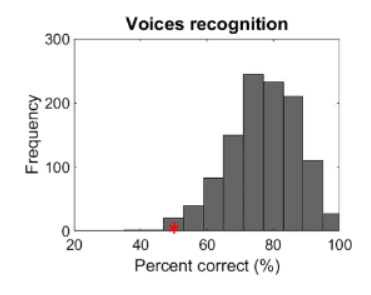
The Glasgow Voice Memory Test
Assessing the ability to memorize and recognize unfamiliar voices
Assesses the ability to encode and immediately
recognize, through an old/new judgment, both unfamiliar voices (vowels, for minimal linguistic content and international use) and bell sounds.
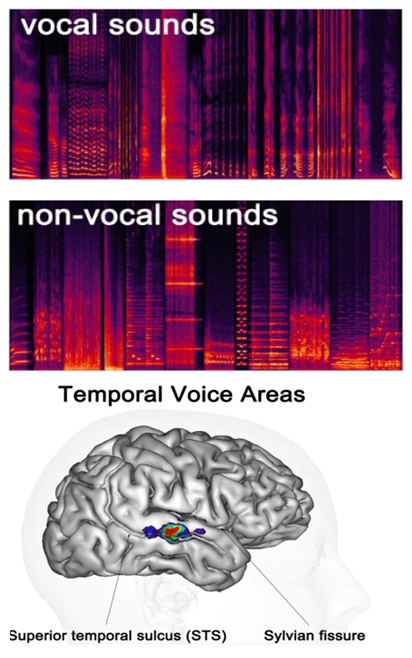
Voice Localizer
Set of stimuli for a functional localizer of the temporal voice areas (TVAs) using neuroimaging
The voice localizer contains 40 8-sec blocs of sounds (16 bit, mono, 22050 Hz sampling rate): 20 blocs (vocal_01 -> vocal_20) consist of only vocal sound (speech as well as nonspeech), and 20 consist of only nonvocal sounds (industrial sounds, environmental sounds, as well as some animal vocalizations). All sounds have been normalized for RMS; a 1kHz tone of similar energy is provided for calibration. See Pernet et al. (2015) Neuroimage